4.4.7. Enzyme Kinetics: The Michaelis-Menten Mechanism#
4.4.7.1. Motivation#
Enzymes are biomolecules (most commonly proteins) that catalyze a wide variety of biochemical reactions. These important molecules facilitate almost every important process in cellular biology. The kinetics of these biological catalysts is of interest for understanding the basic science of how our body works as well as the design of novel industrial chemical syntheses.
4.4.7.2. Learning Goals:#
After working through these notes, you will be able to:
Delineate the steps and approximations in the Michaelis-Menten mechanism for enzyme kinetics.
Express the rate of change of reactant (/substrate) change in terms of Michaelis-Menten parameters.
Use a Lineweaver-Burk plot (/equation) to fit Michaelis-Menten parameters.
Describe how to setup an experiment to measure Michaelis-Menten parameters.
4.4.7.3. Coding Concepts:#
The following coding concepts are used in this notebook:
4.4.7.4. Enzymes are Biological Catalysts#
Enzyzmes are proteins that catalyze chemical reactions. The type of reactions span the gamut of biochemical processes including almost every step of glycolysis to the hydrolysis of ATP in motor proteins. Enzymes are known to speed-up chemical reactions by many orders of magnitude (as much as \(10^5-10^{12}\)).
Without enzymes, life as we know it would not exist. Processes would occur at rates far to slow to sustain life.
So how do enzymes achieve such amazing speed-ups?
4.4.7.5. Proposed Mechanism for Enzyme Catalysis: The Michaelis-Menten Mechanism#
The most ubiquitous, and one of the simplest, mechanisms for enzyme catalysis was proposed my Leonor Michaelis and Maude Menten in 1913. It is still the go-to mechanism for fitting enzyme kinetics. The derivation is as follows.
Consider a generic process of converting a substrate to a product with chemical reaction
where \(S\) is the substrate (aka reactant), \(E\) is the enzyme, and \(P\) is the product. It was found, experimentally, that many enzyme catalyzed reactions of this form followed the rate law
Michealis and Menten proposed a two-step mechanism whereby the enzyme and substrate form an intermediate (called the enzyme-substrate complex) in a reversible reaction, followed by another reversible reaction in which the substrate is converted into product. This can be written as
Note that it is common to assume the second step is irreversible but it is not necessary to do so.
The above mechansim leads to the following three differential equations
Because enzyme is not created or destroyed during the reaction, the overall concentration of enzyme containing species is fixed as the initial concentration of enzyme. That is
Substituting this into the differential equations above gives
These equations cannot be solved analytically for \([S]\), \([E]\), and/or \([P]\) without further approximation.
The first approximation employed is the steady-state approximation for \([ES]\). This approximation is typically valid after an intial phase of building up the \(ES\) concentration when enzyme is mixed with excess substrate. After the initial lag phase, but before much substrate has been consumed and/or product has been formed, the steady-state approximation will be achieved yielding
Substituting the steady-state approximation for the concentration of the enzyme-substrate complex into the differential equation for substrate concentration yields
If we now dictate that we will only measure the intitial rate of the reaction (post lag phase) and that there is only reactant/substrate present initially, then we can make the following approximations
Plugging in these approximations to the Michaelis-Menten rate equation yields
where the last equality holds true for \(K_m = \frac{k_{-1} + k_2}{k_1}\). This quantity is called the Michaelis-Menten constant or the Michaelis-Menten binding constant. Note that this quantity is not the equilibrium constant for the first step in the Michaelis-Menten mechanism.
We see an example plot of initial rate vs. initial substrate concentration below.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# setup plot parameters
fontsize=16
fig = plt.figure(figsize=(8,8), dpi= 80, facecolor='w', edgecolor='k')
ax = plt.subplot(111)
ax.grid(which='major', axis='both', color='#808080', linestyle='--')
ax.set_ylabel("$v_0$ ($\mu$M/s)",size=fontsize)
ax.set_xlabel("$[S]_0$ ($\mu$M)",size=fontsize)
plt.tick_params(axis='both',labelsize=fontsize)
def mm(S0,vmax,Km):
return vmax*S0/(Km + S0)
vmax = 0.001
Km = 10
S0 = np.arange(0,100,0.1)
ax.plot(S0,mm(S0,vmax,Km),lw=3);
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 1
----> 1 import numpy as np
2 import matplotlib.pyplot as plt
3 get_ipython().run_line_magic('matplotlib', 'inline')
ModuleNotFoundError: No module named 'numpy'
We notice from the plot above that the initial rate saturates/plateaus as the initial substrate concentration is increased. Indeed, it is readily shown that the maximum initial rate, denoted \(v_{max}\), is
4.4.7.6. Experiments to Measure Michaelis-Menten Parameters#
For an enzyme catalyzed reaction that follows the Michaelis-Menten mechanism, the parameters \(K_m\) and \(v_{max}\) allow us to determine the rate of reaction at aribtraty substrate concentration. These parameters can be compared amongst enzymes or across experimental conditions to assess the efficiency of an enzyme. Indeed, these parameters are still estimated for a number of enzymes today.
To consider how to design an experiment to estimate these parameters, we start writing out the chemical reaction
and the associated Michaelis-Menten rate equation
We need to measure \(v_0\) as a function of \([S]_0\) to determine \(v_{max}\) and \(K_m\). This can be done in a number of ways but there are two critical components:
Some way of measuring the initial rate of reaction. The specifics of this measurement will depend on the reaction and reaction conditions. An example might be absorbance spectroscopy - if the product absorbs light at a different frequency than the reactant, then measuring absorbance as a function of time will provide the appropriate information.
Performing multiple trials altering the initial concentration of substrate.
After these experiments, one will have concentration (or something proportional to concentration) as a function of initial concentration of substrate. From here, it is a question of fitting the resulting data to the above equation for \(v_0\) to determine v_{max}\( and \)K_m$. This can be done using a non-linear fit or using a Lineweaver-Burke plot.
4.4.7.7. Fitting Michaelis-Menten Parameters using a Lineweaver-Burk Plot#
A Lineweaver-Burk plot is a plot of \(\frac{1}{v_0}\) vs. \(\frac{1}{[S]_0}\) and can be considered a linearized form of the Michaelis-Menten equation.
To demonstrate this, we start with the Michaelis-Menten initial rate equation and take the reciprocal of both sides:
This last equation is known as the Lineweaver-Burk equation and demonstrates that \(\frac{1}{v_0}\) will be linear with respect to \(\frac{1}{[S]_0}\) for enzyme kinetics that is well modeled by the Michaelis-Menten mechanism. The slope of the line will be \(\frac{K_m}{v_{max}}\) and the intercept is \(\frac{1}{v_{max}}\).
4.4.7.8. The Importance of v/K#
The value of \(v_{max}/K_m\) (or, \(k_2/K_m\)), is a measure of the efficiency of an enzyme. To see why this value is important, consider the MM rate law
When \(K_m >> [S]_0\), we have that
or that the reaction is first order in substrate, first order in enzyme, and second order overall with observed rate constant of \(\frac{k_2}{K_m}\).
\(\frac{k_2}{K_m}\) will have units of M\(^{-1}\cdot\)s\(^{-1}\) and is related to the number of collisions that lead to reaction. The higher the value of \(\frac{k_2}{K_m}\) the more efficient the enzyme. Value near \(10^9\) are the maximum indicating that the reaction is diffusion controlled and thus effectively every collision leads to reaction.
4.4.7.9. Comparing MM Parameters For Different Enzymes#
Michaelis-Menten Parameter are tabulated for various enzymes. These can be compared to assess the relative efficiency of these enzymes.
Enzyme |
Substrate |
\(K_m\) (M) |
\(k_{2}\) (s\(^{-1}\)) |
\(\frac{k_2}{K_m}\) (M\(^{-1}\cdot\)s\(^{-1}\)) |
|---|---|---|---|---|
Acetylcholineterase |
Acetylcholine |
\(9.5\times10^{-5}\) |
\(1.4\times10^4\) |
\(1.5\times10^8\) |
Carbonic anhydrase |
CO\(_2\) |
\(1.2\times10^{-2}\) |
\(1.0\times10^6\) |
\(8.3\times10^7\) |
Carbonic anhydrase |
HCO\(_3^-\) |
\(2.6\times10^{-2}\) |
\(4.0\times10^5\) |
\(1.5\times10^7\) |
Catalase |
H\(_2\)O\(_2\) |
\(2.5\times10^{-2}\) |
\(1.0\times10^7\) |
\(4.0\times10^8\) |
In the table above we see various examples of enzymes substrate pairs and their associated Michaelis-Menten parameters. Carbonic anhydrase, for example, can bind either CO\(_2\) or HCO\(_3^-\) and has different MM parameters for those substrates. As a summary, the enzymative efficiency (\(\frac{k_2}{K_m}\)) of Carbonic anhydrase is larger for CO\(_2\) as a substrate as compared to HCO\(_3^-\).
4.4.7.10. Example: Fitting Michaelis-Menten Parameters#
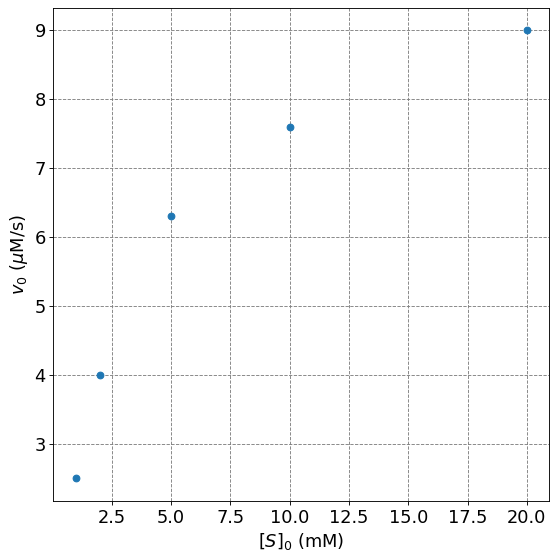
Determine the Michaelis-Menten Paramters from the following data
\([S]_0\) (mM) |
\(v_0\) (\(\mu\)M/s) |
|---|---|
1 |
2.5 |
2 |
4.0 |
5 |
6.3 |
10 |
7.6 |
20 |
9.0 |
4.4.7.10.1. Solution: Non-linear Fitting#
We will simply solve this by performing a non-linear fit to the Michaelis-Menten parameters. We start by entering the data into arrays and plotting it.
# Put the data into numpy arrays
import numpy as np
s0 = np.array([1,2,5,10,20.0])
v0 = np.array([2.5,4.0,6.3,7.6,9.0])
Show code cell source
# plot data
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# setup plot parameters
fontsize=16
fig = plt.figure(figsize=(8,8), dpi= 80, facecolor='w', edgecolor='k')
ax = plt.subplot(111)
ax.grid(which='major', axis='both', color='#808080', linestyle='--')
ax.set_ylabel("$v_0$ ($\mu$M/s)",size=fontsize)
ax.set_xlabel("$[S]_0$ (mM)",size=fontsize)
plt.tick_params(axis='both',labelsize=fontsize)
ax.plot(s0,v0,'o',lw=2);
Show code cell source
# perform non-linear fit
# import least squares function from scipy library
from scipy.optimize import curve_fit
# define Michaelis-Menten function
def mm(s,vmax,Km):
return vmax*s/(Km + s)
# make an initial guess of parameters
x0 = np.array([1.0,1.0])
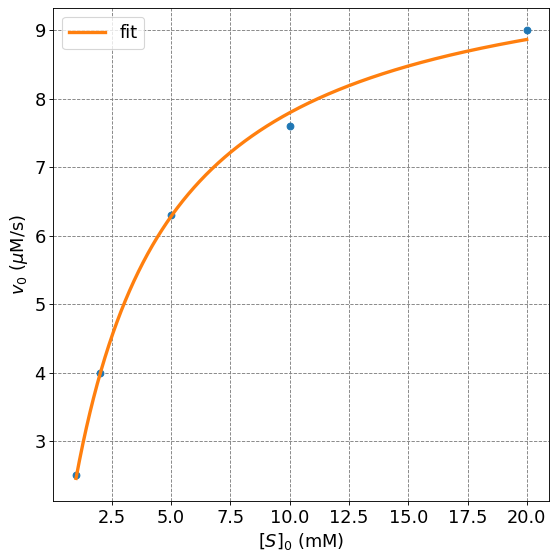
popt, pcov = curve_fit(mm, s0, v0)
err = np.sqrt(np.diag(pcov))
print("v_max = ", np.round(popt[0],1),"+/-", np.round(err[0],1), "muM/s")
print("Km = ", np.round(popt[1],1),"+/-", np.round(err[1],1), "mM")
v_max = 10.3 +/- 0.2 muM/s
Km = 3.2 +/- 0.2 mM
Show code cell source
# plot data
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# setup plot parameters
fontsize=16
fig = plt.figure(figsize=(8,8), dpi= 80, facecolor='w', edgecolor='k')
ax = plt.subplot(111)
ax.grid(which='major', axis='both', color='#808080', linestyle='--')
ax.set_ylabel("$v_0$ ($\mu$M/s)",size=fontsize)
ax.set_xlabel("$[S]_0$ (mM)",size=fontsize)
plt.tick_params(axis='both',labelsize=fontsize)
ax.plot(s0,v0,'o',lw=2)
s = np.arange(np.amin(s0),np.amax(s0),0.01)
ax.plot(s,mm(s,popt[0],popt[1]),lw=3,label="fit")
plt.legend(fontsize=fontsize);
4.4.7.10.2. Solution: Lineweaver-Burk Plot#
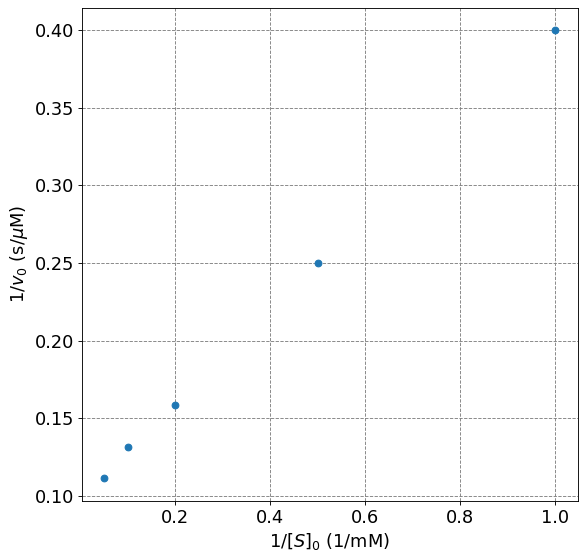
In this solution we will plot \(1/v_0\) vs \(1/[S]_0\) and fit the resulting data to a line.
Show code cell source
# plot data
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# setup plot parameters
fontsize=16
fig = plt.figure(figsize=(8,8), dpi= 80, facecolor='w', edgecolor='k')
ax = plt.subplot(111)
ax.grid(which='major', axis='both', color='#808080', linestyle='--')
ax.set_ylabel("$1/v_0$ (s/$\mu$M)",size=fontsize)
ax.set_xlabel("$1/[S]_0$ (1/mM)",size=fontsize)
plt.tick_params(axis='both',labelsize=fontsize)
ax.plot(1/s0,1/v0,'o',lw=2);
Fit the line to get the MM parameters:
Show code cell source
# perform linear fit
# import least squares function from scipy library
from scipy.optimize import curve_fit
from sklearn.metrics import r2_score
# define Michaelis-Menten function
def mm_lineweaver_burke(s,m,b):
return m*s + b
# perform fit
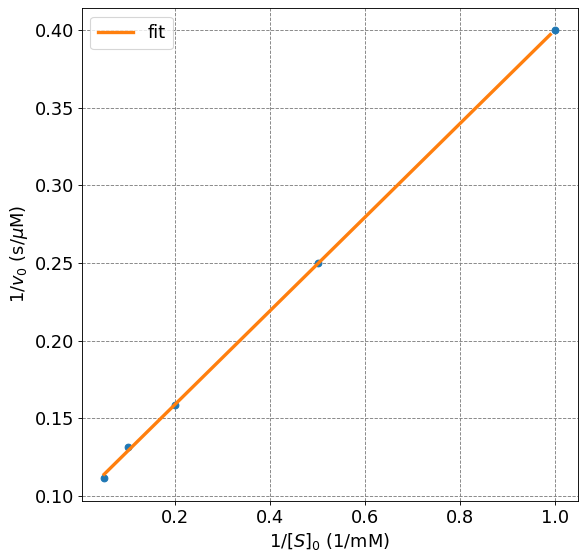
popt_lwb, pcov = curve_fit(mm_lineweaver_burke, 1/s0, 1/v0)
err_lwb = np.sqrt(np.diag(pcov))
print("Slope = ", np.round(popt_lwb[0],3), "+/-", np.round(err_lwb[0],3))
print("Intercept = ", np.round(popt_lwb[1],3), "+/-", np.round(err_lwb[1],3))
y_pred = mm_lineweaver_burke(1/s0,*popt_lwb)
print("R^2 = ", r2_score(1/v0, y_pred))
vmax_lwb = 1/popt_lwb[1]
vmax_lwb_err = vmax_lwb*err_lwb[1]/popt_lwb[1]
Km_lwb = popt_lwb[0]/popt_lwb[1]
Km_lwb_err = Km_lwb*np.sqrt( (err_lwb[0]/popt_lwb[0])**2 + (err_lwb[1]/popt_lwb[1])**2)
print("v_max = ", np.round(vmax_lwb,1),"+/-", np.round(vmax_lwb_err,1), "muM/s")
print("Km = ", np.round(Km_lwb,1),"+/-", np.round(Km_lwb_err,1), "mM")
Slope = 0.302 +/- 0.003
Intercept = 0.099 +/- 0.001
R^2 = 0.9997345039696032
v_max = 10.1 +/- 0.1 muM/s
Km = 3.1 +/- 0.1 mM
Plot the resulting Lineweaver-Burk plot:
Show code cell source
# plot data
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# setup plot parameters
fontsize=16
fig = plt.figure(figsize=(8,8), dpi= 80, facecolor='w', edgecolor='k')
ax = plt.subplot(111)
ax.grid(which='major', axis='both', color='#808080', linestyle='--')
ax.set_ylabel("$1/v_0$ (s/$\mu$M)",size=fontsize)
ax.set_xlabel("$1/[S]_0$ (1/mM)",size=fontsize)
plt.tick_params(axis='both',labelsize=fontsize)
ax.plot(1/s0,1/v0,'o',lw=2)
s = np.arange(np.amin(1/s0),np.amax(1/s0),0.01)
ax.plot(s,mm_lineweaver_burke(s,popt_lwb[0],popt_lwb[1]),lw=3,label="fit")
plt.legend(fontsize=fontsize);
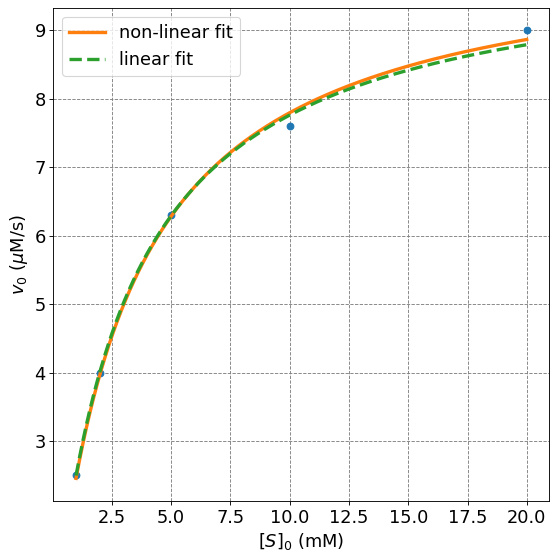
4.4.7.10.3. Compare Solutions#
Show code cell source
# plot data
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# setup plot parameters
fontsize=16
fig = plt.figure(figsize=(8,8), dpi= 80, facecolor='w', edgecolor='k')
ax = plt.subplot(111)
ax.grid(which='major', axis='both', color='#808080', linestyle='--')
ax.set_ylabel("$v_0$ ($\mu$M/s)",size=fontsize)
ax.set_xlabel("$[S]_0$ (mM)",size=fontsize)
plt.tick_params(axis='both',labelsize=fontsize)
ax.plot(s0,v0,'o',lw=2)
s = np.arange(np.amin(s0),np.amax(s0),0.01)
ax.plot(s,mm(s,popt[0],popt[1]),lw=3,label="non-linear fit")
ax.plot(s,mm(s,vmax_lwb,Km_lwb),'--',lw=3,label="linear fit")
plt.legend(fontsize=fontsize);
4.4.7.11. Example: Fitting with Random Error#
Here we consider fitting MM parameters using either the Lineweaver-Burk linearization or non-linear regression. Which method is better? To investigate this, we generate a set of fake data using a known \(K_m\) and \(v_{max}\) and then fit the data using both approaches.
Below is a piece of code that will generate a fake data with random error (a fractional noise around the true value) set for initial concentrations of \(1, 2, 5, 10, 20\) mM. We will use Michaelis-Menten parameters of
Show code cell source
from tabulate import tabulate
s0 = np.array([1,2,5,10,20.0])
# Generate a data set
def mm_from_params(S0,vmax,Km):
return vmax*S0/(Km + S0)
vmax = 7.5
Km = 4.0
truth = mm_from_params(s0,vmax,Km)
n_trials = 5
data = np.empty((truth.shape[0],n_trials))
s0_total = np.empty((s0.shape[0],n_trials))
for i in range(n_trials):
# estimate error based on normal distribution 99.9% data within 7.5%
error = np.random.normal(0,0.03,truth.shape[0])
# estimate error from uniform distribution with maximum value of 5%
#error = 0.1*(np.random.rand(truth.shape[0])-0.5)
# generate data by adding error to truth
data[:,i] = truth*(1+error)
# keep flattened s0 array
s0_total[:,i] = s0
combined_data = np.column_stack((s0,data))
print(tabulate(combined_data,headers=["[S]0","Trial 1", "Trial 2", "Trial 3", "Trial 4", "Trial 5"]))
[S]0 Trial 1 Trial 2 Trial 3 Trial 4 Trial 5
------ --------- --------- --------- --------- ---------
1 1.54005 1.48224 1.54493 1.54319 1.53409
2 2.56303 2.55978 2.57401 2.45028 2.50472
5 3.97056 4.2554 4.04871 4.22324 4.33101
10 5.51357 5.35767 5.68042 5.54163 5.18707
20 6.2559 6.28182 6.22688 6.05313 6.43527
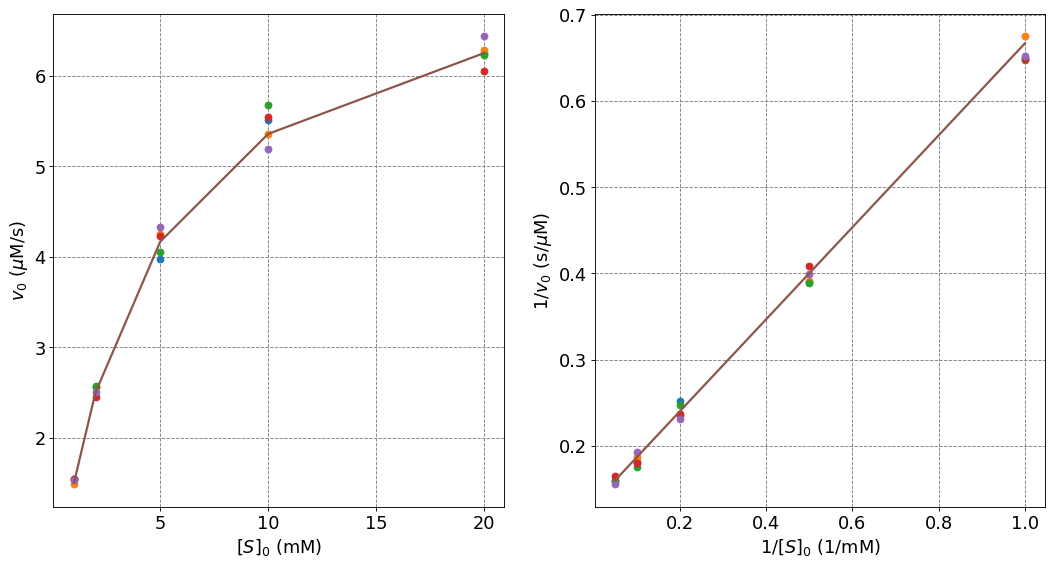
The data in both standard and linear form look like:
Show code cell source
# plot data
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# setup plot parameters
fontsize=16
fig, ax = plt.subplots(1,2,figsize=(16,8), dpi= 80, facecolor='w', edgecolor='k')
ax[0].grid(which='major', axis='both', color='#808080', linestyle='--')
ax[0].set_ylabel("$v_0$ ($\mu$M/s)",size=fontsize)
ax[0].set_xlabel("$[S]_0$ (mM)",size=fontsize)
ax[0].tick_params(axis='both',labelsize=fontsize)
for i in range(n_trials):
ax[0].plot(s0,data[:,i],'o')
ax[0].plot(s0,truth,'-',lw=2,label="Truth")
ax[1].grid(which='major', axis='both', color='#808080', linestyle='--')
ax[1].set_ylabel("$1/v_0$ (s/$\mu$M)",size=fontsize)
ax[1].set_xlabel("$1/[S]_0$ (1/mM)",size=fontsize)
ax[1].tick_params(axis='both',labelsize=fontsize)
for i in range(n_trials):
ax[1].plot(1/s0,1/data[:,i],'o')
ax[1].plot(1/s0,1/truth,'-',lw=2,label="Truth");
Now to perform the fits. We start with the linear least-squares using the Lineweaver-Burk formulation.
Show code cell source
# perform linear fit
# import least squares function from scipy library
from scipy.optimize import curve_fit
# define Michaelis-Menten function
def mm_lineweaver_burke(s,m,b):
return m*s + b
# make an initial guess of parameters
popt_lwb, pcov = curve_fit(mm_lineweaver_burke, 1/s0_total.flatten(), 1/data.flatten())
err_lwb = np.sqrt(np.diag(pcov))
vmax_lwb = 1/popt_lwb[1]
vmax_lwb_err = vmax_lwb*err_lwb[1]/popt_lwb[1]
Km_lwb = popt_lwb[0]/popt_lwb[1]
Km_lwb_err = Km_lwb*np.sqrt( (err_lwb[0]/popt_lwb[0])**2 + (err_lwb[1]/popt_lwb[1])**2)
print("v_max = ", np.round(vmax_lwb,1),"+/-", np.round(vmax_lwb_err,1), "muM/s")
print("Km = ", np.round(Km_lwb,1),"+/-", np.round(Km_lwb_err,1), "mM")
v_max = 7.5 +/- 0.1 muM/s
Km = 3.9 +/- 0.1 mM
Now we perform non-linear least squares using the standard Michaelis-Menten rate equation.
Show code cell source
# perform non-linear fit
# import least squares function from scipy library
from scipy.optimize import curve_fit
# define Michaelis-Menten function
def mm(s,vmax,Km):
return vmax*s/(Km + s)
# make an initial guess of parameters
x0 = np.array([1.0,1.0])
popt, pcov = curve_fit(mm, s0_total.flatten(), data.flatten())
err = np.sqrt(np.diag(pcov))
print("v_max = ", np.round(popt[0],1),"+/-", np.round(err[0],1), "muM/s")
print("Km = ", np.round(popt[1],1),"+/-", np.round(err[1],1), "mM")
v_max = 7.5 +/- 0.1 muM/s
Km = 3.9 +/- 0.1 mM
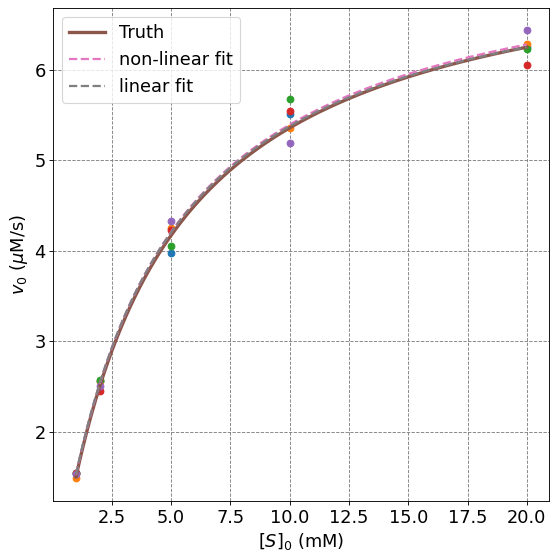
You can see that both methods produce reasonable results. They can be compared visually by looking at the plot.
Show code cell source
# plot data
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# setup plot parameters
fontsize=16
fig, ax = plt.subplots(1,1,figsize=(8,8), dpi= 80, facecolor='w', edgecolor='k')
ax.grid(which='major', axis='both', color='#808080', linestyle='--')
ax.set_ylabel("$v_0$ ($\mu$M/s)",size=fontsize)
ax.set_xlabel("$[S]_0$ (mM)",size=fontsize)
ax.tick_params(axis='both',labelsize=fontsize)
for i in range(n_trials):
ax.plot(s0,data[:,i],'o')
s = np.arange(1,20,0.01)
ax.plot(s,mm(s,vmax,Km),'-',lw=3,label="Truth")
ax.plot(s,mm(s,popt[0],popt[1]),'--',lw=2,label="non-linear fit")
ax.plot(s,mm(s,vmax_lwb,Km_lwb),'--',lw=2,label="linear fit")
plt.legend(fontsize=fontsize);
4.4.7.12. Example: Fitting with Systematic Error#
Now we will investigate how the two fitting procedures deal with systematic error. This error is a fixed value rather than a percentage of each true result. This is a better mimic of an error for a given instrument. Below is a piece of code that will generate a fake data with systematic error for initial concentrations of \(1, 2, 5, 10, 20\) mM. We will use Michaelis-Menten parameters of
Show code cell source
from tabulate import tabulate
s0 = np.array([1,2,5,10,20.0])
# Generate a data set
def mm_from_params(S0,vmax,Km):
return vmax*S0/(Km + S0)
vmax = 7.5
Km = 4.0
truth = mm_from_params(s0,vmax,Km)
n_trials = 5
data = np.empty((truth.shape[0],n_trials))
s0_total = np.empty((s0.shape[0],n_trials))
for i in range(n_trials):
# estimate error based on normal distribution 99.9% data within 7.5%
error = np.random.normal(0,0.1,truth.shape[0])
data[:,i] = truth+error
# keep flattened s0 array
s0_total[:,i] = s0
combined_data = np.column_stack((s0,data))
print(tabulate(combined_data,headers=["[S]0","Trial 1", "Trial 2", "Trial 3", "Trial 4", "Trial 5"]))
[S]0 Trial 1 Trial 2 Trial 3 Trial 4 Trial 5
------ --------- --------- --------- --------- ---------
1 1.51114 1.55358 1.44833 1.3177 1.51512
2 2.51471 2.50878 2.42385 2.58492 2.50417
5 4.25496 3.9962 4.11779 4.22525 4.23454
10 5.30692 5.50917 5.32731 5.48786 5.43156
20 6.25687 6.25135 6.12554 6.44108 6.23428
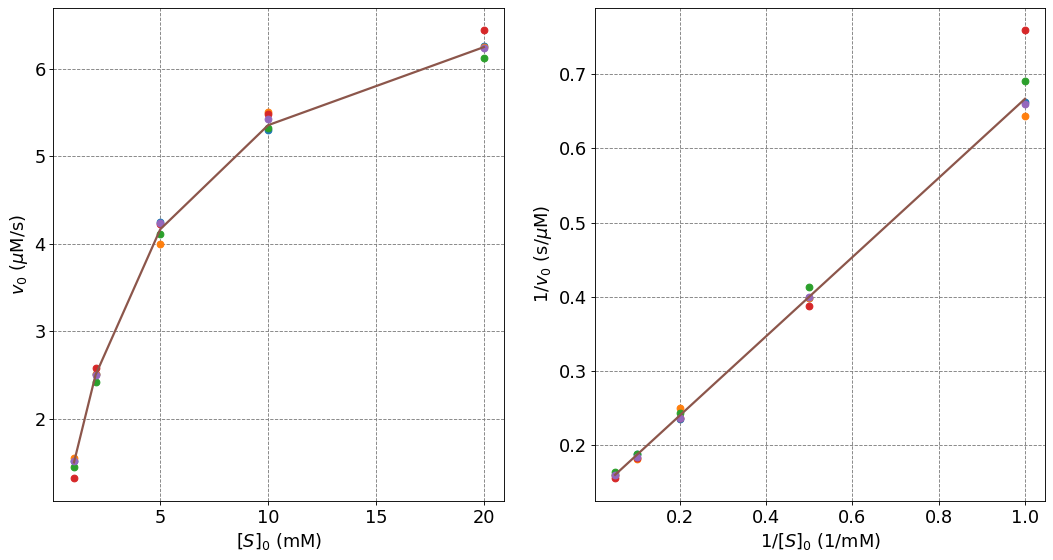
Show code cell source
# plot data
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# setup plot parameters
fontsize=16
fig, ax = plt.subplots(1,2,figsize=(16,8), dpi= 80, facecolor='w', edgecolor='k')
ax[0].grid(which='major', axis='both', color='#808080', linestyle='--')
ax[0].set_ylabel("$v_0$ ($\mu$M/s)",size=fontsize)
ax[0].set_xlabel("$[S]_0$ (mM)",size=fontsize)
ax[0].tick_params(axis='both',labelsize=fontsize)
for i in range(n_trials):
ax[0].plot(s0,data[:,i],'o')
ax[0].plot(s0,truth,'-',lw=2,label="Truth")
ax[1].grid(which='major', axis='both', color='#808080', linestyle='--')
ax[1].set_ylabel("$1/v_0$ (s/$\mu$M)",size=fontsize)
ax[1].set_xlabel("$1/[S]_0$ (1/mM)",size=fontsize)
ax[1].tick_params(axis='both',labelsize=fontsize)
for i in range(n_trials):
ax[1].plot(1/s0,1/data[:,i],'o')
ax[1].plot(1/s0,1/truth,'-',lw=2,label="Truth");
Non-linear fit:
Show code cell source
# perform non-linear fit
# import least squares function from scipy library
from scipy.optimize import curve_fit
# define Michaelis-Menten function
def mm(s,vmax,Km):
return vmax*s/(Km + s)
# make an initial guess of parameters
x0 = np.array([1.0,1.0])
popt, pcov = curve_fit(mm, s0_total.flatten(), data.flatten())
err = np.sqrt(np.diag(pcov))
print("v_max = ", np.round(popt[0],1),"+/-", np.round(err[0],1), "muM/s")
print("Km = ", np.round(popt[1],1),"+/-", np.round(err[1],1), "mM")
v_max = 7.6 +/- 0.1 muM/s
Km = 4.1 +/- 0.1 mM
Linear-fit
# perform linear fit
# import least squares function from scipy library
from scipy.optimize import curve_fit
# define Michaelis-Menten function
def mm_lineweaver_burke(s,m,b):
return m*s + b
# make an initial guess of parameters
popt_lwb, pcov = curve_fit(mm_lineweaver_burke, 1/s0_total.flatten(), 1/data.flatten())
err_lwb = np.sqrt(np.diag(pcov))
vmax_lwb = 1/popt_lwb[1]
vmax_lwb_err = vmax_lwb*err_lwb[1]/popt_lwb[1]
Km_lwb = popt_lwb[0]/popt_lwb[1]
Km_lwb_err = Km_lwb*np.sqrt( (err_lwb[0]/popt_lwb[0])**2 + (err_lwb[1]/popt_lwb[1])**2)
print("v_max = ", np.round(vmax_lwb,1),"+/-", np.round(vmax_lwb_err,1), "muM/s")
print("Km = ", np.round(Km_lwb,1),"+/-", np.round(Km_lwb_err,1), "mM")
v_max = 7.7 +/- 0.3 muM/s
Km = 4.2 +/- 0.2 mM
In this case, we see that the non-linear fit produces values closer to the true values as compared the the Lineweaver-Burk linearization. This is why it is suggested to use non-linear fitting.